下一代AI为先的产品形态,交互方式应该是更自然的拟人形态,并不局限于语音文字交流。
应该即是具身智能,拟人交互。又是跨屏跨端,无处不在。
还应该在AR的加持下,全感官、沉浸场景式交互。
论大模型时代的原生产品
目前没找到免费试用资源。
ChatGLM-6B:这是一个开源的中英双语对话模型,具有 62 亿参数。该模型在单张消费级显卡上即可进行推理使用。它使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。ChatGLM-6B 具备充分的中英双语预训练和优化的模型架构等特点。
https://mp.weixin.qq.com/s/3X-u6QrziP8cQGngZkcfBw 如何打造一个大模型生成的数据目录?
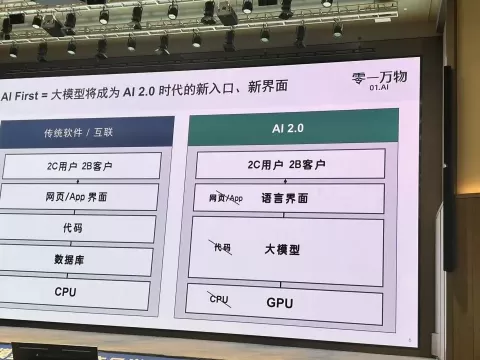
大模型带来对用户交互、应用场景、商业机会的革新思考
https://github.com/modelscope/swift
Swift是一个提供LLM模型轻量级训练和推理的开源框架。Swift提供的主要能力是efficient tuners,tuners是运行时动态加载到模型上的额外结构,在训练时将原模型的参数冻结,只训练tuner部分,这样可以达到快速训练、降低显存使用的目的。比如,最常用的tuner是LoRA。
在这个框架中提供了以下特性:
可运行的模型Examples:针对热门大模型提供的训练脚本和推理脚本,并针对热门开源数据集提供了预处理逻辑,可直接运行使用
LLM 是无状态(stateless)的,大参数量使产品无法基于每一次交互的经验来更新模型的内部参数。不过由于 LLM 能理解大量语义信息,Agent 系统可以在模型之外建立一个记录信息的记忆系统,来模仿人类大脑那样从过往的经验中学习正确的工作模式。
以下分类根据医学中人类的几种记忆方式类比,将 AI agent 的记忆系统分为短期记忆与三种长期记忆:
短期记忆:
• 工作记忆(Working Memory):这一轮决策所需要用到的所有信息。其中包括上下文内容,例如从长期记忆中检索到的知识;也包括 LLM context 以外的信息,例如 function call 时使用其他能力所产生的数据
长期记忆:
• 事件记忆(Episodic Memory):Agent 对过去多轮决策中所发生事情的记忆。每一次 LLM 有了新的行为和结果,agent 都会把内容写进情节记忆。例如在 Generative agents 小镇中,虚拟小镇的 agent 居民会把自己每天看到的事、说过的话计入事件记忆。要使得用户得到个性化的使用体验,这一部分的优化是至关重要的。
预训练是大型语言模型训练流程的第一阶段,其目标是在大规模数据集上学习语言的通用表示。这个过程使模型能够捕捉语言的基本结构和模式,理解单词、短语和句子的语义,以及这些元素如何在不同的上下文中交互。预训练模型通常使用无监督或自监督的学习方法,这意味着它们不需要人工标记的训练数据。通过预训练,模型可以构建一个广泛的知识基础,这可以在之后的微调阶段针对特定任务进行优化。
预训练模型的一个典型例子是GPT(Generative Pre-trained Transformer),它使用了大量的文本数据进行预训练,以掌握语言生成的能力。此外,BERT(Bidirectional Encoder Representations from Transformers)通过预训练来更好地理解语言中的双向上下文关系。
预训练不仅仅是模型训练流程的起点,更是确保模型在各种语言处理任务上具备强大通用性和适应性的关键步骤。随着预训练技术的不断进步,我们可以期待模型在更多复杂任务上表现出色,如对话系统、自然语言理解、文本摘要等。
零样本学习 Zero-shot Learning