在科学哲学的视角下,当前大语言模型(LLM)的根本悖论在于“休谟问题”的重现:单纯的统计归纳(频率与概率)永远无法推导出逻辑的必然(因果与真理)。大模型既非枯燥的统计学暗箱,也非完美的柏拉图理念世界。它是一个被经验暴力挤压出的崎岖地貌,在上下文的临时扭曲下进行局部概率滑落,并亟需外部逻辑验证器来为其建立刚性边界的动力学系统。要真正理解这种硅基智能,我们必须跨越工程学的参数规模,将其认知过程拆解为“经验的流形”与“先验的法则”之间的动态博弈。
硅基认知的几何动力学:大模型的广义相对论与人工认识论

在科学哲学的视角下,当前大语言模型(LLM)的根本悖论在于“休谟问题”的重现:单纯的统计归纳(频率与概率)永远无法推导出逻辑的必然(因果与真理)。大模型既非枯燥的统计学暗箱,也非完美的柏拉图理念世界。它是一个被经验暴力挤压出的崎岖地貌,在上下文的临时扭曲下进行局部概率滑落,并亟需外部逻辑验证器来为其建立刚性边界的动力学系统。要真正理解这种硅基智能,我们必须跨越工程学的参数规模,将其认知过程拆解为“经验的流形”与“先验的法则”之间的动态博弈。

自然规律奖励的不是瞬间最大功率,而是全生命周期的总耗散量。生命是耗散能量的超级机器。
复制就是共振:如果一个结构能复制自己,那么它消耗能量、制造熵的能力就会呈指数级增长。
自然界没有永恒的朋友或敌人,只有能量效率的共同体。
Trae + Claude 3.7 Sonnet:大致75分,还是需要手工修一些代码,并且有的Bug反复尝试10次以上,人工辅助定位了位置,但始终无法修复。可惜就是免费限流了。
Trae + DeepSeek-R1:大致70分。幻觉多一些,也会偷懒,出错概率高于 Claude 3.7 。
VSCode + Cline + Gemini 2.0 Flash Thinking:大致70分。Gemini 2.0上下文窗口很大,可以一次性快速生成超多代码,具备多模态能力,都是加分项。拖后腿的是 Cline,对IDE的集成度、RAG策略还是不够,导致经常陷入Bug反复修改无效。Cline 的MCP功能很好。
VSCode + 通义灵码 + qwen2.5-max :60分以下,因为通义灵码对整个IDE的集成度不够。在不指出引用文件情况下,会导致完全孤立的去修改一个文件,导致全局灾难。

实时生成数字人视频,成本很高。本文构想了一种浏览器端的数字人方案,借助于AI生成2D模型,成本很低,可交互反馈,适用于教学、培训、动漫等场景。
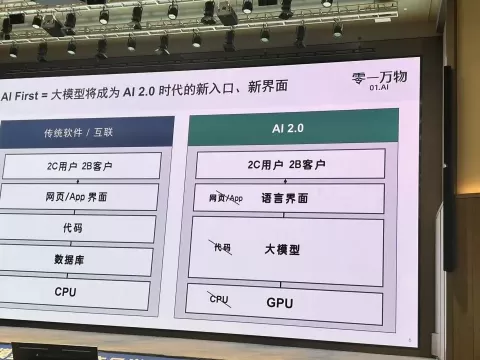

思考=模型=知识。泛化:举一反三的能力是泛化。语言,给我们带来最根本的能力,是零样本泛化能力,用来沟通只是语言的副产品。人类有了语言,所以才有第二系统,才能思考。
三位一体结构演化模式:感知(信息系统)→ 思考(模型系统) → 实现(行动系统)

主导公司大数据平台产品建设,涵盖 数据采集、主数据管理、数仓、数据服务、标签 几大产品。
主数据管理:建立医百主数据管理系统,主要支持对 医院、医生、药品、会议海报、数据字典 进行人工编辑、审核。
数仓:采用维度建模范式,提供 人、机构 的OneID产品逻辑,HCP、HCO、医学知识、学术等数据模型定义。
指标体系:建立含58个原子指标、70+项维度的指标体系。
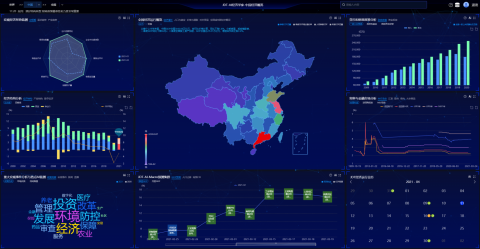
建立宏观经济数据库及AI经济学家,对内提升宏观投研效率,对外提供宏观经济自动化解读。宏观经济数据库:企业自有产权的宏观经济数据库,涵盖中国宏观、区域宏观、世界宏观、产业经济等类别数据。宏观经济分析大屏:面向政府及企业高层决策部门,提供对全球、中国乃至区域宏观经济的分析解读及预测。

2019年,联邦学习作为数据合作的新兴技术,开始在国内传播。我对其进行了学习研究,并应用到了京东数据联盟、钼媒数据平台中。
传统数据打通:把特征或标签数据整合到一方,同时利用双方数据进行训练得到模型,存在隐私数据出库、数据资产外流的弊端。
联邦学习:数据拥有方在不用给出己方原始数据的情况下,也可进行联合训练(交换加密训练参数)并得到足够准确的模型(与传统数据打通建立模型的差距很小),且训练目标为非个体信息或经过用户授权,各方无法反推他方原始数据。
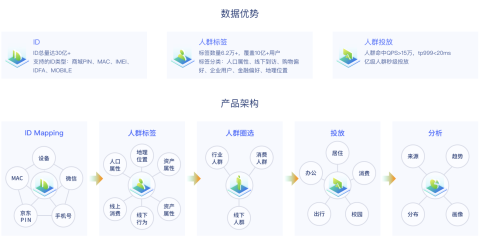
京东钼媒数据平台 是数字营销生态部门的数据集市,整合了集团内外部的线下特色数据能力。目标是以数据智能为核心,驱动线下营销业务发展,赋能广告主客户。